Optimized Locking, Part I
One of the newer features introduced in Azure SQL Database is "Optimized Locking". But what does that mean, and how does it compare to the apparently "un-optimized" locking the SQL relational engine has been using up to this point? Let's dive in and take a look.

Simply put, TID locking changes lock behavior by taking a lock on a transaction ID, and holding it for the duration of the transaction in place of other, more numerous, locks being held for that same duration. Locks on other resources, such as Row IDs and keys, are still taken, but are released immediately after an update occurs instead of being held until the transaction ends.
Say we are running an UPDATE statement that will affect a large number of rows. Without optimized locking, this might involve acquiring one exclusive (X) lock for each row, and holding them all until the end of the transaction. (Let us not consider lock escalation in this case.) Meanwhile, with optimized locking, all those X locks would still be needed, but could be released as soon as each row is updated, and only a single TID lock would be held until the transaction commits. Holding each X lock for a shorter period of time will result in reduced memory consumption (because each lock consumes memory while it exists).
Let's do a side-by-side comparison and see this in action!
Traditional Locking
For this part, I spun up SQL Server 2022 on an Azure Virtual Machine. I created a table, loaded some sample data into it, and created an index.
1CREATE DATABASE TestDB22;
2GO
3
4USE TestDB22;
5GO
6
7CREATE TABLE dbo.TheTable (
8 Id INT NOT NULL,
9 Payload CHAR(5400) NOT NULL
10);
11
12INSERT INTO dbo.TheTable(Id, Payload)
13SELECT value, 'X'
14FROM GENERATE_SERIES(1, 10000);
15
16CREATE UNIQUE INDEX ix_Ids ON dbo.TheTable(Id);With everything set up, now begin a transaction and update some of the rows. With the transaction still open, query sys.dm_tran_locks to see what locks are being held. Remember, these locks are held until the transaction either commits or rolls back.
1BEGIN TRAN
2
3UPDATE dbo.TheTable
4SET Payload = 'Y'
5WHERE Id BETWEEN 200 AND 250;
6
7SELECT resource_type, resource_description, request_mode, request_type
8FROM sys.dm_tran_locks
9WHERE request_session_id = @@SPID;I see 104 total locks being held by this transaction which is updating 51 rows. Scrolling down and taking a screenshot, there's plenty of X (eXclusive) locks on RID (row id), one for each row, as well as IX (Intent eXclusive) locks on each affected page, and some others in there too. So long as the transaction is open, these locks will be held, consuming resources as well as potentially blocking other operations from occurring.
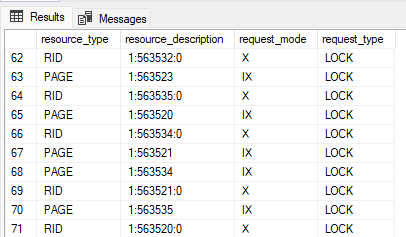
1COMMITOh, and let's not forget to commit the transaction at this point - we wouldn't want an open transaction hanging around longer than necessary!
Optimized Locking
Given that we just saw how regular (classic?) locking behaves, now let's look at optimized locking. In an Azure SQL Database I'll run the same commands. First, make sure the database is in compatibility level 160 (otherwise GENERATE_SERIES won't work), and then create the table, data and index.
1ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 160;
2
3CREATE TABLE dbo.TheTable (
4 Id INT NOT NULL,
5 Payload CHAR(5400) NOT NULL
6);
7
8INSERT INTO dbo.TheTable(Id, Payload)
9SELECT value, 'X'
10FROM GENERATE_SERIES(1, 10000);
11
12CREATE UNIQUE INDEX ix_Ids ON dbo.TheTable(Id);Now I'll run the same query to open a transaction, update 51 rows, and check for active locks.
1BEGIN TRAN
2
3UPDATE dbo.TheTable
4SET Payload = 'Y'
5WHERE Id BETWEEN 200 AND 250;
6
7SELECT resource_type, resource_description, request_mode, request_type
8FROM sys.dm_tran_locks
9WHERE request_session_id = @@SPID;Do things look a little different this time?
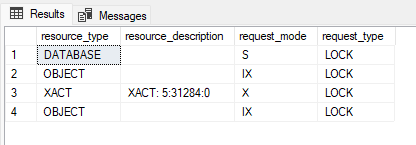
Yep, only 4 locks are being held at this point, and only one of them is exclusive: the one with resource type XACT, which means it's a Transaction ID lock.
It's very important I point out that other locks were taken, because an X lock on the row is required for an update to occur. But with optimized locking, those X locks were also released immediately after each row was updated - they are no longer held for the length of the transaction like they were in the first demo.
1COMMITAnd once again, don't forget to commit that open transaction!
Findings
Optimized locking not only introduces a new type of lock that can be taken on transaction IDs, but also changes locking behavior by reducing the amount of time exclusive locks are held. Whenever locks are held for a shorter period of time, fewer resources such as memory are necessary to manage them. I have run into cases in the past where servers have run out of lock memory, so this is a welcome step towards reducing issues of this type.
All in all, I think optimized locking is an amazing feature and a great leap forward for database fundamentals. I will absolutely be diving in and showing off some of its other features in future posts!