Does Data Compression Speed Up Datatype Changes?

Can datatypes be changed faster with data compression enabled?
I've always replied that I'm pretty sure compression will help in this situation, because based on my understanding, it should. But I've never had any actual data to back up this belief. Until now. I recently set up a demonstration to test this, and I'm very happy to share the results.
The Demo
I ran this demo using SQL Server 2022 running on an Azure Virtual Machine. If you would like the full demo script to run on your own, you can find it here. I'll step through it below to better explain things. To determine how much database activity has been generated - and thus if a size-of-data operation is occurring, I'm using three different methods:
- SSMS Time & IO Statistics
- Amount of transaction log generated as observed from running a log backup
- Amount of transaction log generated as observed from the sys.dm_db_log_stats DMV
And with that, let's start this demo off by enabling time and IO statistics and creating a database.
1SET STATISTICS TIME ON;
2SET STATISTICS IO ON;
3
4CREATE DATABASE [TestDB]
5 ON PRIMARY
6( NAME = N'TestDB', FILENAME = N'F:\data\TestDB.mdf' , SIZE = 1GB , FILEGROWTH = 1GB )
7 LOG ON
8( NAME = N'TestDB_log', FILENAME = N'G:\log\TestDB_log.ldf' , SIZE = 256MB , FILEGROWTH = 1GB )
9GO
10ALTER DATABASE [TestDB] SET RECOVERY SIMPLE
11GONow let's enter the TestDB database we just created, create 2 tables and populate them with data. I'm creating a numbers table and then using that to populate our main set of records, which I am lovingly calling TheTable. TheTable has 2 columns: Id, an identity integer, and a Payload. I'm populating each row's payload with a random GUID that's being repeated in order to generate a long string and help grow the size of the table quickly. This may take a few minutes to complete.
1USE TestDB;
2
3CREATE TABLE dbo.Numbers (
4 i INT NOT NULL
5);
6
7CREATE TABLE dbo.TheTable (
8 Id INT IDENTITY(1,1) NOT NULL,
9 Payload CHAR(5400) NOT NULL
10);
11
12-- populate numbers table to 1M
13WITH cteN(i) AS (
14 SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id]) - 1
15 FROM sys.all_columns AS s1
16 CROSS JOIN sys.all_columns AS s2
17)
18INSERT INTO dbo.Numbers(i)
19SELECT i
20FROM cteN
21WHERE i <= 1000000;
22
23-- fill TheTable with 2M rows
24INSERT INTO dbo.TheTable (Payload)
25SELECT REPLICATE(CONVERT(CHAR(36), NEWID()), 150)
26FROM dbo.Numbers n1
27CROSS JOIN dbo.Numbers n2
28WHERE n2.i < 2;Once that's done, let's find out how large the table is, both in terms of MB and number of pages.
1-- get size of each table in MB
2SELECT
3 t.name AS TableName,
4 s.name AS SchemaName,
5 p.rows,
6 CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
7 CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
8 CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
9FROM sys.tables t
10INNER JOIN sys.indexes i ON t.object_id = i.object_id
11INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
12INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
13LEFT JOIN sys.schemas s ON t.schema_id = s.schema_id
14WHERE t.is_ms_shipped = 0
15GROUP BY t.name, s.name, p.rows
16ORDER BY TotalSpaceMB DESC, t.name;
17
18-- see page_count column for number of pages
19SELECT *
20FROM sys.dm_db_index_physical_stats (DB_ID('TestDB'), OBJECT_ID('dbo.TheTable'), NULL, NULL, 'SAMPLED');In my tests, the table grew to 15625 MB and 2000000 pages. Hopefully you arrive at similar results.
With the database created and full of test data, let's set the recovery model to FULL and take both full and transaction log backups. This will give us a backup of the database as it was created, as well as ensuring the transaction log is as clear as possible.
1ALTER DATABASE TestDB SET RECOVERY FULL;
2
3BACKUP DATABASE TestDB
4TO DISK = 'D:\Backup\TestDB.bak'
5WITH COMPRESSION, INIT, FORMAT;
6
7BACKUP LOG TestDB
8TO DISK = 'D:\Backup\TestDB_1.trn'
9WITH COMPRESSION, INIT, FORMAT;Now let's see how many changes are sitting in the transaction log waiting to be backed up. Since we just ran a backup, this number should be very low. The sys.dm_db_log_stats DMV has this info:
1SELECT log_since_last_log_backup_mb
2FROM sys.dm_db_log_stats (DB_ID('TestDB'));I see an incredibly low number, 0.097656 MB. To me, this means there's some tiny amount of data in the transaction log - likely about the most recent checkpoint, but that's probably it since no other operations have been run on this database since the last backup.
We're ready to take action and change the datatype of the Id column from INT to BIGINT. This is a large change so it will likely take some time to complete.
1ALTER TABLE dbo.TheTable ALTER COLUMN Id BIGINT;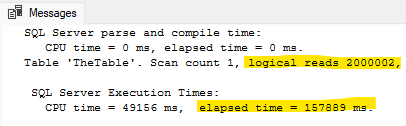
The time and IO statistics collected by SSMS show me that this operation took 157889 ms (or about 158 seconds), and performed 2000002 reads.
Remember from above that the table has 2000000 pages, so this is most definitely a "size of data" operation involving changing every row in the table. Let's also query the log stats DMV again and see how much transaction log was generated by this change:
1SELECT log_since_last_log_backup_mb
2FROM sys.dm_db_log_stats (DB_ID('TestDB'));I see 272 MB of changes in the log. Take a log backup and let's see how large that backup ends up being.
1BACKUP LOG TestDB
2TO DISK = 'D:\Backup\TestDB_BigInt_1.trn'
3WITH COMPRESSION, INIT, FORMAT;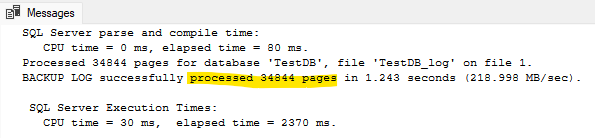
SSMS tells me the backup contained 34844 pages, which when multiplied by 8KB also comes out to 272 MB.
At this point, we've created a database, changed the datatype, and seen what the effects of that change were in terms of runtime and effort required. Now we need to do that all again, but this time with data compression enabled. Fortunately we have a backup of the database which allows us to re-run our test with identical data.
We will now restore the database from the full backup created above, enable ROW compression, and then take full and transaction log backups. Once again these operations will take some time.
1USE master;
2
3RESTORE DATABASE TestDB
4FROM DISK = 'D:\Backup\TestDB.bak'
5WITH REPLACE;
6
7USE TestDB;
8
9ALTER TABLE dbo.TheTable REBUILD
10WITH (DATA_COMPRESSION = ROW);
11
12BACKUP DATABASE TestDB
13TO DISK = 'D:\Backup\TestDB_RowCompress.bak'
14WITH COMPRESSION, INIT, FORMAT;
15
16BACKUP LOG TestDB
17TO DISK = 'D:\Backup\TestDB_RowCompress_1.trn'
18WITH COMPRESSION, INIT, FORMAT;With all these operations complete, check and make sure the log is empty (or very close to it).
1SELECT log_since_last_log_backup_mb
2FROM sys.dm_db_log_stats (DB_ID('TestDB'));It returns 0.070312 MB of log space from the above query.
With everything in place, let's once again change the datatype of the Id column to BIGINT.
1ALTER TABLE dbo.TheTable ALTER COLUMN Id BIGINT;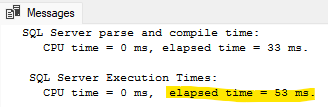
Is that operation a little faster this time? SSMS statistics tells me that 0 pages were read, and the operation took 53 ms. Contrast this with 2M pages and 158 seconds previously!
So how many changes are now sitting in the transaction log?
1SELECT log_since_last_log_backup_mb
2FROM sys.dm_db_log_stats (DB_ID('TestDB'));I see 0.074218 MB, or just a tiny bit larger than before the type change occurred.
Finally, let's back up the transaction log one more time to ensure it's really that empty:
1BACKUP LOG TestDB
2TO DISK = 'D:\Backup\TestDB_RowCompress_BigInt_1.trn'
3WITH COMPRESSION, INIT, FORMAT;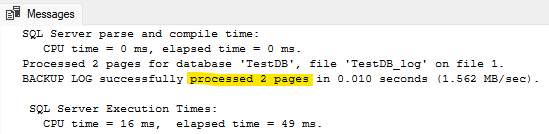
A grand total of 2 pages are included in this backup. So yes, the changes really were that small. But even more important than that, this operation went from taking 158 seconds to 0.053 seconds. By my math this appears to be a 99.97% decrease in runtime!
Findings
In conclusion, if you are using data compression and change the datatype of a column, there can be a significant performance benefit over situations without compression. Row compression is all that is necessary to achieve these benefits, however the benefits are the same with page compression as well, because page compression starts by applying row compression and then performs additional operations. (I did also run this test with page compression, but am not including the syntax for it here because it's basically identical. Feel free to try it yourself if you'd like!)
Why This Works
So why does changing a datatype become so much faster when data compression is present? This has to do with what data compression is doing behind the scenes, which is transparently modifying data types by taking fixed-width types and making them variable-width.
As their name suggests, fixed-width datatypes consume a fixed amount of space regardless of the value they are storing. Let's look at a simple example:
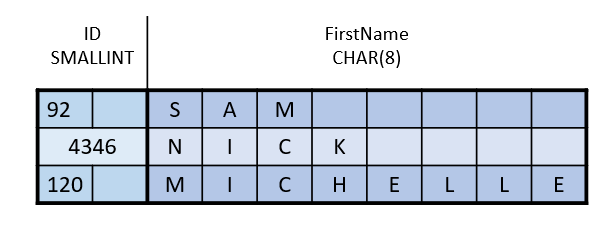
This table has 2 columns: a SMALLINT and a CHAR(8), which require 2 and 8 bytes respectively. They require this much space regardless of the values they are storing. The first row has an ID value of 92, which can be stored in a single byte (remember, a single byte can store the values 0 to 255), but because the datatype is SMALLINT, it's consuming two bytes. The second row, with ID of 4346, requires both bytes to store a value that large.
The second column of datatype CHAR(8) is similar, the second row with the value "Nick" only requires 4 bytes, but because CHAR(8) is a fixed-width datatype, all rows require 8 bytes. Since the database engine arranges each row such that all fixed-width columns are written before any variable-width columns, each fixed-width column will have the same offset in every row. This can be observed here - the third byte is always the beginning of the FirstName column. This makes things simple and predictable.
When row compression is enabled on this table, it now looks like this:
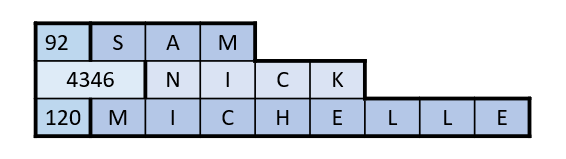
Several changes should be apparent here. First of all, the unused space has been eliminated, resulting in considerable space savings. Without compression, each row required 10 bytes. Now the first row requires only 4 bytes, a 60% savings! Another difference is that the column offsets are no longer consistent - the second column begins in either the second or third byte depending on the values stored in the row. This new arrangement of variable widths for fixed-width datatypes requires a new data format for each row, and adds a new data structure called a column descriptor, or "CD". The CD describes each column and how many bytes it is consuming in this particular row.
Here's what the first row in our record looks like when viewed with DBCC PAGE:
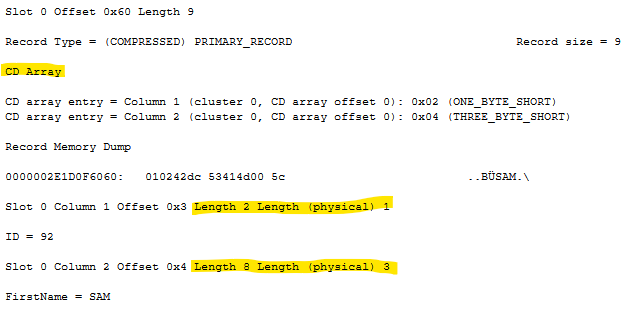
You will notice the CD array contains two entries, one for each column. Below the CD, you'll find the values for each column with the mention of both the column's length and it's physical length. The ID value of 92, for example, has a length of 2 because it's a SMALLINT which occupies 2 bytes, however its physical length is only 1, because only one byte is needed to store the value 92 with row compression enabled.
When data is queried, the CD in each row is used to locate the compressed value, which is then transformed to the datatype specified in the table's definition and returned to the client. This makes data compression transparent to end users and applications, as the data returned by the database is identical with or without compression.
This transformation from a compressed format to whatever datatype is specified by the table definition is what so greatly increases the speed of a datatype change. As an example, say we need to change a CHAR(5) column to CHAR(10). This means a 5 byte fixed-width column will need to grow to 10 bytes.
Without compression, each row in the table will need to be changed. Since a 5 byte column will be replaced by 10 bytes, each column written after it will be shifted to the right by 5 bytes. If there's not enough space on an 8KB data page for all these rows which have now grown larger, a page split will occur, creating even more writes. All this makes a datatype change a "size of data" operation, as each row needs to be written, and the more rows the table has, the longer it will take. If we want to be all computer science-y, we can call this a O(n) operation ("big O of n"), meaning there's a linear relationship between data size and runtime.
With data compression enabled, each data row is already in a format which is based on the value being stored and mostly* independent of the actual data type being used. Because of this, if a column's data type changes, the rows don't have any need to change, and all that needs to be updated is the table definition. Since the table only has one definition to change regardless of its size, the runtime is now constant. In computer science class this is known as a O(1) operation ("big O of 1"), meaning a constant relationship between data size and runtime. This is much preferred over O(n) because as we just observed, it means things will be significantly faster.
To sum everything up, if you have data compression enabled, then congratulations - should you ever need to change the datatype of a column, it should be an extremely quick operation!
* I say "mostly independent" because this optimization only works if you are changing between different sizes of the same type of data, such as changing from INT to BIGINT or from CHAR(5) TO CHAR(20). This wouldn't work if you tried to change a column from INT to CHAR(5), but hopefully you're not trying to do that anyway!