What Is A SQL Server Big Data Cluster?
SQL Server Big Data Clusters (BDCs) are a highly anticipated feature of SQL Server 2019, but what are they – and how can their capabilities best be leveraged? Let's dig a little deeper and find out.
When SQL Server 2017 added support for Linux, the groundwork was laid for integrating SQL Server with Spark, HDFS, and other big data tools which are typically Linux-based. Big Data Clusters in SQL Server 2019 delivers on these integration possibilities and allows for both relational data and big data to be easily combined and analyzed.
Big Data Clusters leverage enhancements to PolyBase in SQL Server 2019 to allow virtualization of data from a wide variety of sources through external tables. External tables allow data not physically located on the local SQL Server instance to be queried as if it were, and even joined to local tables to produce seamless result sets. Data from remote SQL Server instances, Azure SQL Database, Azure Cosmos DB, MySQL, PostgreSQL, MongoDB, Oracle, and many other sources can all be accessed through PolyBase external tables. In a BDC, the SQL Server engine also features built-in support for HDFS, and can join all these datasets together, allowing easy integration of both relational and non-relational data.
Apache Spark is also deeply integrated into a Big Data Cluster, enabling data scientists and engineers to access and manipulate the data described above in a scalable, distributed, in-memory compute layer. This data can then be used for machine learning, AI, and other analysis tasks.
How Does a Big Data Cluster Work?
Architecturally speaking, Big Data Clusters are clusters of containers (such as Docker containers). These scalable clusters run SQL Server, Spark, HDFS, and other services. Every aspect of a BDC runs in a container, and all these containers are managed by Kubernetes, a container orchestration service. Groupings of containers, known as pods, are grouped into pools which make up the main components of a Big Data Cluster:
- Master Instance: A SQL Server 2019 instance that serves as the main connection endpoint for SQL queries, and stores metadata and read/write user databases in the BDC. When restoring a database backup into a BDC, this would also be the target. For HA purposes this can also be an availability group.
- SQL Data Pool: A collection of SQL Server instances that datasets can be sharded across, allowing scale-out query capabilities for frequently-accessed data. This can be very useful for storing large tables that would otherwise reside on the master instance. It is also a great location to cache results of complex queries that join multiple external data sources.
- Storage Pool: A scalable storage tier hosting HDFS, Spark, and SQL Server. Unstructured and semi-structured data files, such as parquet or delimited text, can be stored here and accessed via SQL Server external tables or any other tool which can connect to HDFS.
- Compute Pool: A collection of SQL Server compute nodes that allow for scale-out processing by facilitating queries from the master instance that need to access the SQL data pool or storage pool. The compute pool is not directly accessed by end users.
- Application Pool: A set of interfaces allowing applications using the R, Python, SSIS, and MLeap runtimes to run on the BDC and have access to its data and computational resources.
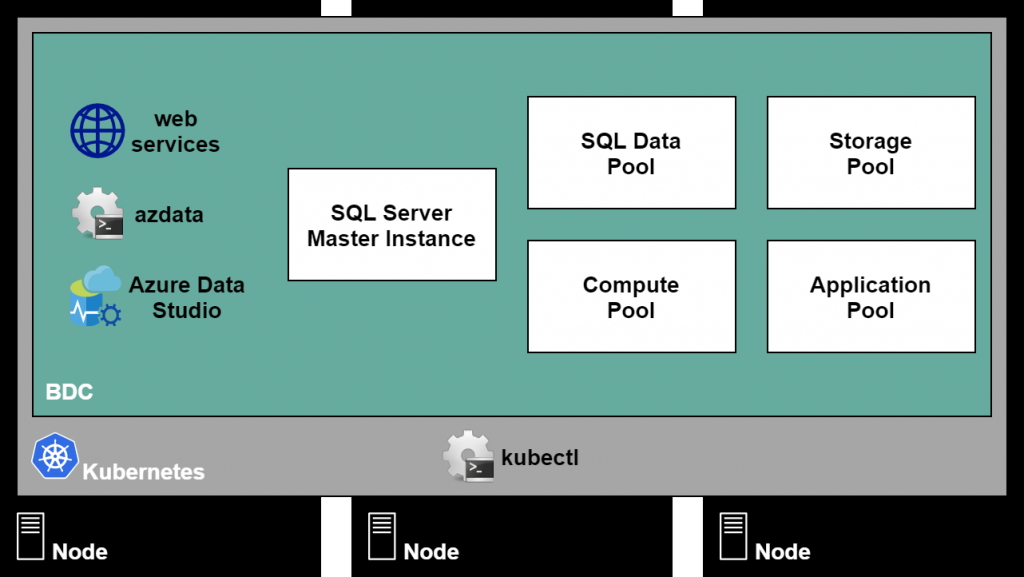
As can be seen from the diagram, BDCs contain several other components such as web services for monitoring and management of the cluster and its components, and azdata, a CLI for management of the BDC.
For those who prefer to use a GUI, Azure Data Studio can play a significant role in the management of Big Data Clusters. In addition to SQL Server tasks, ADS allows you to create and manage a BDC, perform HDFS tasks such as uploading and downloading files, create external tables through wizards, run T-SQL, Spark, and Python notebooks, and more. While certainly not required, Azure Data Studio is a great environment to perform a lot of common BDC tasks in.
What are some key use cases for Big Data Clusters?
Envision managing a data warehouse for a major retailer, with transaction data coming in regularly from store locations and the website. While some data in the warehouse is definitely relational and should be stored as such, the millions of daily transactions delivered via delimited text files, is not.
While an ETL process could be used to load all of this data into a relational database, it would add an extra layer of complexity, create another process to maintain, and take time to execute. Leveraging a SQL Server Big Data Cluster would enable the 'big data' for transactions to be stored in their native format and analyzed without further processing. Additionally, both relational and big data can be combined by joining physical and virtual tables just like any other SQL query. Furthermore, the big data is available for analysis with Spark, R, or any other application which can access data stored in HDFS.
The flexibility provided by a SQL Server Big Data Cluster allows for many use cases, but some of the most common are scenarios that require:
- Combining relational data, non-relational data, and/or big data
- Immediate access to data through data virtualization
- The ability to query the same data through both SQL Server and Spark without duplication
- A consistent solution that can be deployed within Azure, in other public clouds, or on premises
To sum things up, SQL Server Big Data Clusters are a very welcome and innovative addition to the Microsoft Data Platform that help build on SQL Server's capabilities and give it incredible amounts of flexibility and scalability.